
by Matthew Gaskill
Some time ago, you decided that you wanted to know more about yourself and your family history beyond what the paper trail revealed, so you purchased a DNA kit. Like me, you likely had a number of questions answered and were faced with a surprise or two. If you’re the curious type (and you probably are because you’re reading this article!), you now have even more questions about your DNA results and genetic genealogy in general.
Perhaps you’re ready to take yet another step and have even more questions answered. And that’s where GEDmatch comes in. Read on to find out how to use your raw DNA data to discover more about your genetic past through this free resource.
You’ll need your raw DNA data to use GEDmatch and the article explains how to gather it from your testing provider. But if you haven’t already taken a test, you’ll need to do that first. This DNA guide will help you compare all of the top tests so you can choose the best one for you.
How To Use GEDmatch to Get More From Your DNA Test
Get ready for the rabbit hole, Alice, because I am going to introduce you to GEDmatch!
The name derives from GEDCOM, or “Genealogical Date Communication”, the protocol developed by the Church of Latter Day Saints to allow people and institutions to develop and share genealogical information.
GEDmatch allows you to upload your DNA and run it through some of the same algorithms/programs that the leading DNA genealogists in the world use. Your DNA results will be a bit more in-depth than your others but, if you have patience and do a little research, GEDmatch will open your eyes and mind even wider to your own genetic history. Best of all, it’s quite simple to use…and free!
To use GEDmatch, you need your raw DNA data. This is provided at no cost from the company you purchased your DNA test kit from. Each genealogy DNA testing company provides an easy way for you to access your raw DNA file. Here are the instructions you will need for each one.
- How to download your DNA from 23andMe
- How to download your DNA from MyHeritage DNA
- How to Download your DNA from Family Tree DNA
- How to download your DNA from Ancestry DNA
You’ll only be able to download your raw data from sites you purchased an actual test kit through. Not those you uploaded your DNA to.
Your raw DNA will come in a .zip file which contains a .txt file with your DNA stored inside. You can open the file to see what you look like in print (it looks like binary code, plus letters representing your genes and amino acid groups.) Do not edit or make any changes to this file though, or it will be essentially useless, no matter how small the changes.
Set Up an Account and Upload Your DNA File
Once you have this file, you’re ready to join GEDmatch. Once again, it’s free – but given the sensitivity of DNA information, you will be required to set up a password and login. And if you’re wondering about GEDmatch’s privacy policy you can find it here. You should always read a privacy policy before uploading your information to a site. Although GEDmatch has been around for a long time and is highly regarded and trusted by the genetic genealogy community.
Once you have completed the (free) registration, look in the upper right corner of the page and you will see the file upload option. Upload the .zip file you downloaded – not just the .txt file. Instructions are also provided as to how to gather your needed file if you haven’t already. Don’t get confused with the GEDCOM upload. This would be a copy of your family tree and you can skip this for now – although if you become active on GEDmatch you should consider using this option. 
The next step is to let GEDmatch process your DNA file. This does not take long, usually a matter of a just few minutes depending on your internet connection and time of day (however, the GEDmatch servers do get busy sometimes, especially after the holidays when most DNA testing companies have just offered deep discounts.) Each kit will be assigned a different unique kit/code number, “A12121” for example. For privacy reasons this number does not correlate with your actual kit number from your provider, except to sometimes include the first letter of the testing company – such as A for Ancestry. This is not always the case though.
Now that you have uploaded your DNA to GEDmatch it is time to have some fun.
Editor’s Note: This article focuses on the DNA reports most people are interested in, Admixture. But one additional section that anyone can use quite easily is the One-to-Many tool. This will allow you to compare your DNA against everyone in the GEDmatch database to see who you are related to. Because teaming up with genetic cousins on research can be so valuable we recommend you explore this area after reading the information below.
Simply click on the link provided in the Analyze Your Data section and enter your GEDmatch kit number (or select it from the dropdown list.) Leave the other settings alone and select “Display Results.” You will then be brought to a page with your matches, sorted by most DNA shared. Each person provides an email for contacting, but it is a good idea to verify that distant matches are correct using the One-to-One comparison tool before reaching out. For help making sense of this information in your research we have covered it in detail in the DNA section of our course, The Genealogy Journey.
GEDmatch offers many interesting things to do with your raw data once it is uploaded, but most of you (if you’re just starting out on the path of DNA family history) will want to start simply. If you scroll down on the main GEDmatch page, you will see “Your DNA Resources,” which will list all of the raw data you uploaded by kit number and name. To the right of that section, you will see a highlighted area labeled “Analyze Your Data.”

Since you’ve come to GEDmatch to increase your knowledge of your own DNA genealogical history, stick with the “admixture” tools at first. (The tools for eye color, etc, are interesting and simple – but some of the others, while relatively simple to use, open up a whole new can of worms and the information can sometimes overwhelm and discourage.)
Note: Once you are comfortable with using and interpreting the admixture results, you will find that both your knowledge and familiarity have grown and the other research tools on the site will not be as daunting.
So, what does “admixture” mean? What will you see once you run your data through these tools?
Very simply put, your admixture is the amount of DNA from different population groups that exist in you. Over time, each generation leaves its DNA traces within the next. For example, if you have exclusively Swedish grandparents on one side of your family, and exclusively Japanese on the other, your admixture (very simply stated) is Japanese/Swedish. (Of course, this does not take into account more distant generations, but you understand my meaning.) Your admixture is everything you are – from a DNA genealogy standpoint.
Now the mechanics. This is where it gets a bit tricky, so follow closely.
It doesn’t really matter which tool you begin with: “Admixture (heritage)” or “Admixture/Oracle with population search.. Let’s use a couple of examples to help you choose:
Let’s say that you already know for sure (from either your own knowledge or the DNA results that you’ve received) what the most significant portions of your DNA history are – English, West African, etc. If you know this, go to the “Admixture/Oracle with population search.” (The “Admixture (heritage)” option will eventually lead you to the “Oracle” option as another choice during this process).

Once you have typed in a population name – you can do this an infinite amount of times for the same or different populations – press “find.” Don’t worry if you make a mistake or have more than one genetic background you wish to investigate further. You will then be presented with a page titled “Admixture/Oracle Population Search Utility,” and a list of what might seem to you to be unintelligible jargon. It’s not – like any other terminology, once you understand it, it comes easy.
Let’s take a couple of examples. I know from extensive prior research that my father’s line (father to father to father to the mists of time) originated in Norway. When I enter “NOR” in the box above and move to the next page, I am presented with a list of choices. On the far left, there is a menu button. Moving to the right, the columns read “MDLP Project,” the middle column will give me some choices (for example “MDLP K11 Modern”/MDLP K16 Modern/Eurogenes Eutest V2 K15”, etc.)
These names signify the name of a research and/or university project and are algorithms that analyze your raw DNA information to determine what your genetic make-up is. For example, “MDLP” stands for “Magnus Ducatus Lituanie Project,” designed and administered by two genetic genealogists in Eastern Europe. The MDLP project, as well as Eurogenes, are the better algorithms for you to use if you’re researching a European background. On the other hand, if you are researching your Persian/Iranian background, you would be better off choosing another of the algorithms, such as “PuntalDNAL,” or “HarappaWorld.”
Here is a sample from MDLP World:
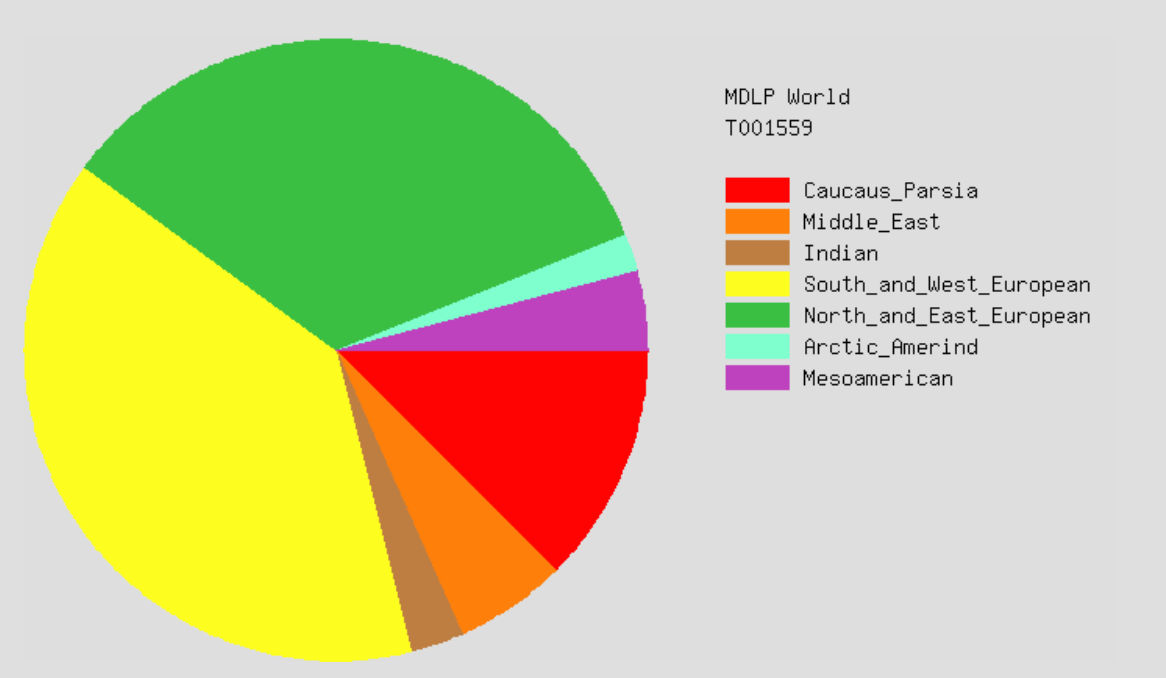
Why? Isn’t my data the same no matter what you put them through?
Yes and no.
The developers of each project had an original aim in mind, and while many of them have since extended their population findings over time, each researcher/team is focused on specific populations. To do this, they need(ed) not only some specific population data, but a large enough sample from each.
Hence, the MDLP project originally used mostly samples from Europe (and more specifically, northern and eastern Europe) to attempt to answer their early research questions. The same (generally) holds true for the others. Now, with the development of the science and the popularity of genetic DNA kits, raw DNA data is exploding and the older projects have expanded to include more populations and newer projects have sprung up.
I have run my DNA through virtually all of the choices on GEDmatch. For someone who had/has no knowledge whatever of their background this can be daunting. However, most people have at least some small idea, and that is key because DNA testing and paper knowledge go hand in hand. Working with just one of these is fine, but together they will give you a much better picture, and also allow you to dismiss results which do not add up. (Remember, DNA genealogy is still in its relative infancy.) Read more about interpreting your results here.
Let’s use my results as an example: I know from both personal research and experience that my mother’s parents and their families are from a large Greek island off the coast of Turkey – at least as far back as three to five hundred years. Additionally, one part of my maternal grandfather’s line likely was Armenian, many generations ago.
This I know, but a surprise arrived when all of my genetic tests came back and said I had a greater portion of identifiable Italian DNA than Greek. This made sense to me, however, for the island that mom’s family comes from was colonized by the Genoese of Italy for hundreds of years. Does this make me any less “Greek”? No, that is the culture my family has celebrated for centuries. Just makes life more interesting and creates more mysteries – I told you earlier that this would happen!
My father’s side is more difficult because his many grandparents hailed from different parts of northern Europe and the UK. However, with the aid of FamilyTreeDNA’s extensive testing options (which are NOT free), I know that my direct line starting from my earliest recognizable paternal ancestor came from the border area of southern Norway/western Sweden.
So, with that information, I can read my GEDmatch results with more clarity. For those of you with less knowledge at this point, don’t worry – it will come. GEDmatch can be addicting and can lead you to places that you likely never thought of.
Though I have run my raw data through most of the choices the most recommended algorithm for me is the Eurogenes EUtest V2 K15 4-Ancestors Oracle. Below are the findings:
Admix Results (sorted):
| # | Population | Percent |
| 1 | North_Sea | 22.42 |
| 2 | East_Med | 15.96 |
| 3 | Atlantic | 15.44 |
| 4 | West_Asian | 14.09 |
| 5 | West_Med | 13.28 |
| 6 | Baltic | 7.99 |
| 7 | Eastern_Euro | 6.54 |
| 8 | Red_Sea | 2.45 |
Finished reading population data. 207 populations found. 15 components mode. Least-squares method.
Using 1 population approximation:
1 Romanian @ 11.515497
2 Serbian @ 12.463036
3 Greek_Thessaly @ 12.817530
4 Bulgarian @ 13.231844
5 Tuscan @ 13.828128
6 North_Italian @ 14.957923
7 Italian_Abruzzo @ 15.302434
8 Greek @ 16.520313
9 Central_Greek @ 17.792519
10 French @ 18.064939
11 Ashkenazi @ 18.294338
12 East_Sicilian @ 18.576559
13 West_Sicilian @ 18.688026
14 Hungarian @ 18.799595
15 Spanish_Galicia @ 19.088011
16 West_German @ 19.122713
17 Austrian @ 19.373152
18 Moldavian @ 19.431915
19 Portuguese @ 19.462379
20 Spanish_Extremadura @ 20.515163
Using 2 populations approximation:
1 50% Central_Greek +50% West_German @ 4.641745
Using 3 populations approximation:
1 50% French +25% Armenian +25% Serbian @ 4.551045
Using 4 populations approximation:
1 Armenian + French + Greek_Thessaly + West_Norwegian @ 1.798019
2 Armenian + Greek_Thessaly + Southwest_English + West_German @ 1.903644
3 Armenian + French + Greek_Thessaly + Norwegian @ 2.027084
4 Armenian + Greek_Thessaly + Southeast_English + West_German @ 2.383919
5 Armenian + French + Greek_Thessaly + Swedish @ 2.400400
6 Armenian + North_Italian + West_German + West_German @ 2.484885
7 Armenian + Greek_Thessaly + Spanish_Galicia + West_Norwegian @ 2.523763
8 Armenian + Norwegian + Tuscan + West_German @ 2.555770
9 Armenian + Greek_Thessaly + Orcadian + West_German @ 2.568212
10 Armenian + Tuscan + West_German + West_German @ 2.577538
11 Georgian_Jewish + Greek_Thessaly + Southwest_English + West_German @ 2.596363
12 Armenian + Greek_Thessaly + North_Dutch + West_German @ 2.613259
13 Armenian + Swedish + Tuscan + West_German @ 2.650202
14 French + Georgian_Jewish + Greek_Thessaly + West_Norwegian @ 2.669043
15 Armenian + French + Greek_Thessaly + North_Dutch @ 2.714207
16 Armenian + Greek_Thessaly + West_German + West_Scottish @ 2.722297
17 Armenian + Greek_Thessaly + South_Dutch + West_Norwegian @ 2.731227
18 Armenian + French + Greek + West_Norwegian @ 2.739657
19 Greek_Thessaly + Turkish + West_German + West_German @ 2.743714
20 Armenian + Greek_Thessaly + West_German + West_German @ 2.751721
Done. Elapsed time 2.6220 seconds.
As you can see, it took only 2.6 seconds for this to be run! Now for the results…
Analyzing Your DNA Results on GEDmatch
If you keep a couple of things in mind as we review my results and/or analyze yours, the basic concepts of genetic genealogy and GEDmatch will start to make sense. Keep it simple at first. If you try to skip ahead, look up too many terms and dive too deep into the seriously scientific aspects of this by going to read university studies and genome results right away, you may get confused and discouraged.
Our first box above is labeled “Admix Results (sorted).” Read this instead as the “Very Distant Past.” At the top of the list, you will see the population that this particular algorithm finds you most similar to (don’t stop here and say “That’s ridiculous!” – a few things will become clearer as you read on).
You can see here that generally speaking, millennia (yes, millennia) ago, the people that can first be recognized as my ancestors sprung up in various places in the Mediterranean Basin and Northern Europe. Though many intervening years and events have taken place since my family developed into what it is today, this makes sense to me, knowing that my ancestry came primarily from these areas based on prior knowledge and other DNA results. One must also remember that virtually all of your DNA testing results are a look back into the past – essentially before the world became smaller with the development of rapid world travel and human migration.
The next column is called “1 Population approximation.” I could explain this (or try) in many pages, or simplify it by telling you that these results are saying the bulk of my DNA heritage comes from (or closely resembles) these populations. Again, this makes sense, because I know that my mother’s people basically remained in the Mediterranean/Southeastern Europe area until very recently, whereas my branches of my father’s line truly spread out.
Moving on to the next group (again, think of this as moving forward in time). This is a balance, essentially of both sides of my family, and again, it makes sense.
You ask, why doesn’t it say “Greek” or “Norwegian”? Firstly, this is an approximation. Secondly, remember what you are looking at here is not 2018 – you are looking backward in distant time, DNA style.
Coming closer to the present day is our third grouping. Here it reports French, Armenian and Serbian. Again, one has to know a little bit more about history and DNA genealogy to analyze this correctly.
If you have done some reading on genetic genealogy, you know a little about maternal/paternal haplogroups (essentially the genetic Adam/Eve of your family). In my case, I know that my mother’s haplogroup moved from Spain through the Alps region and into the Greece/Mediterranean area. In my father’s case, his haplogroup originated in the area of central France/Flanders and moved northwards. Keeping this in mind, the findings in the third paragraph are consistent with what I know.
The last group moves us up into the more modern era. To make it easy, imagine this as a time before Europeans really moved out into the world.
So, divide the four populations in two – one side my mother’s and one side my father’s. On my mother’s side (once again, generally speaking) we show a close similarity to Armenian/Thessaly(Greece) and Italian. Hi Mom. On the other, we have West German/Norwegian/English (“Skol!”, Dad).
Note: If you’re disappointed that this is not revealing to you exactly what you’re made up of genetically, don’t be. These are the labels that the geneticists who designed these particular algorithms gave them. Again, the science of DNA genealogy is still in its relative infancy. We are seeing explosions in the number of people who are submitting their DNA for analysis (and therefore, comparison) and in the development of new data analytics and DNA tools.
The “Admixture (heritage)” tool (the other choice I mentioned at the beginning of this article), will immediately ask you which program (Eurogenes, Dodecad, etc) you wish to process your raw DNA data through. You can easily pick another variation of the same program (which includes more or fewer samples, for example), or an entirely different one. Experiment to see what works best for you!
If you look around the GEDmatch site you will see many other interesting tools, such as “Are you parents related?” Don’t panic – if they are, it’s likely they had a common relative in 1650 or earlier. I will tell you, that by using the “One to One Compare” tool and then the “People who match one or both of 2 kits” tool, that my girlfriend and I discovered we were either fifth or sixth cousins, matched on my father’s side – she is more than half Swedish, so this again makes sense.
All of this information is yours for free and by uploading your data (anonymously) you are helping the science of DNA genealogy to advance. You can always help even more and make a donation which will allow you to access some of the even more interesting tools available on GEDmatch in the “Tier 1” category.
Good luck!
Matthew Gaskill holds an MA in European History and writes on a variety of topics from the Medieval World to WWII to genealogy and more. A former educator, he values curiosity and diligent research. He is currently working on a novel based on his own family history.
You Might Also Like:
GEDCOM was developed by The Church of Jesus Christ of Latter-day Saints. There is no “Church of Latter-day Saints”